Member-only story
In a previous Medium article, I discussed using Amazon Polly as a method of converting my print articles to audio. While I presented a Lambda script to take a file from S3 and generate an MP3 audio file, I didn’t discuss the why and how of Amazon Polly.
Polly is a text to speech platform capable of handling both plain text and Speech Synthesis Markup Language (SSML). If you want to think of it this way, Amazon Polly and Amazon Transcribe are opposite services. Polly provides text to speech, while Transcribe provides speech to text. Since Polly takes text and converts it to audio, we might think of Amazon Polly as a media service. Both Amazon Polly and Amazon Transcribe are part of the AI/ML service family provided by AWS.
Polly creates very lifelike audio from the supplied text in a variety of voices and dialects. When using plain text with Polly, the punctuation in the text is used as cues for pauses and breaks. Even with plain text, Polly can generate pretty realistic audio. Much more granular control over breaks, intonation, and speed are available using SSML.
Text is converted either using Amazon Polly in the AWS Console, through the AWS Command Line Interface (CLI) or an API provided by the AWS Software Development Kit and your application code. Let’s have a look at creating a simple audio file using Amazon Polly in the AWS Console.
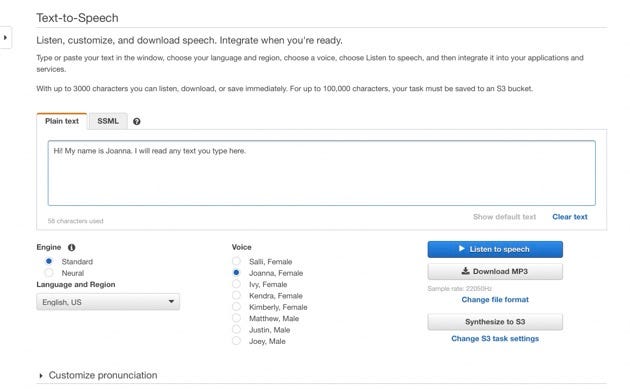
We can type our text in the text box, select the sample rate (Standard or Neural), select the voice, and then either listen to the audio file immediately, download the MP3 file, or save the file to an S3 bucket.
This is what our audio sounds like.
(If the audio player doesn’t show up, click on this link.)
Once the text has been converted, it can be used over and over again in applications or served from a storage location like Simple Storage Service (S3). Polly also supports real-time audio streaming, so the text sent using the API is returned immediately for use in your application.
